发布日期:2024-11-19 04:28 点击次数:169
NCBI的参考序列(RefSeq)计划,为多种生物提供序列的数据信息及相关资料,用于医学、基因功能和基因功能比较研究。
RefSeq数据库中所有的数据是一个非冗余的、提供参考标准的数据,包括染色体、基因组(细胞器、病毒、质粒)、蛋白、RNA等。RefSeq数据库被设计成每个人类位点挑出一个代表序列来减少重复,是NCBI提供的校正的序列数据和相关的信息。数据库包括构建的基因组contig、mRNA、蛋白和整个染色体。refseq序列是NCBI筛选过的非冗余数据库,一般可信度比较高。
而genbank是一个开放的数据库,对每个基因都含有许多序列。很多研究者或者公司都可以自己提交序列,另外这个数据库每天都要和EMBL和DDBJ交换数据。genbank的数据可能重复或者不准。

那么如何在BLAST结果和在Entrez搜索结果里
怎样快速地区分出哪些是RefSeq?
1.ACCESSION,形式为**_#####,其中**为两个字母,其不同组合又可以区分为蛋白序列、核酸序列或基因组序列,而#为位数不等的数字;ACCESSION后面又会加版本号,以**_####.#形式表示,最后的尾数不同表示序列信息有所修改,数字越大版本越新。
2.GI,是GenBank Id的缩写,是序列的ID号,为唯一标识符。这是Genbank的收录号,也是查询号。
4557284 就是该序列的gi号,ref :标示该序列是参考序列。NM_000646.1 该序列的Accession号和版本号。
一般来说,mRNA、蛋白和基因组序列是我们常用到的序列。找标准序列时,mRNA就采用NM_编码的,蛋白就查找NP_编码,基因组用NC_或者AC_编码的。下面是常见的一些编码的汇总。
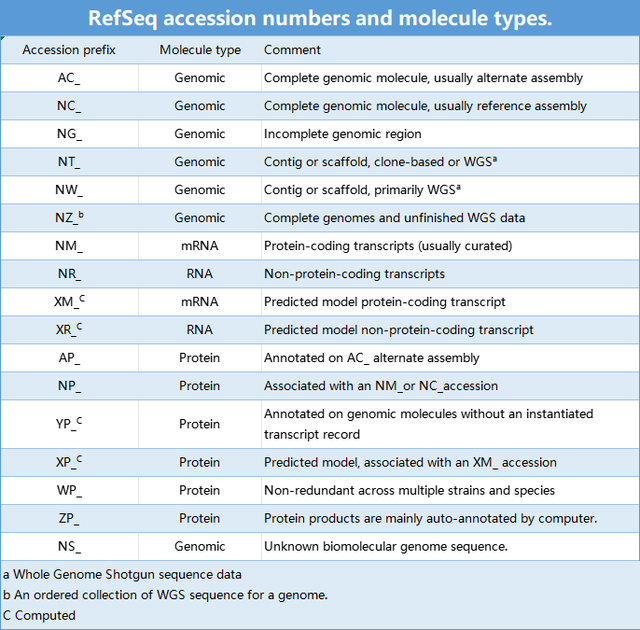
1、“NM_”、“XM_”命名的记录代表的是编码基因,“NM_”对应“NP_”,“XM_”对应“XP_”;
2、“XM_”,“XR_”通过计算机算法预测得到,而“NM_”和“NR_”都是有一定的实验数据支撑,但并不是说“XM_”和“XR_”就不存在于细胞中。
NCBI RefSeq一直在更新,这些命名的记录代表的是一种状态,经常会碰到某个“XM_”记录被“NM_”代替,或者“NM_”记录由于缺少证据而从NCBI RefSeq删除。
上一篇:没有了
下一篇:没有了